【PythonでWEBスクレイピング】ヘッダ情報を付与する

前回、基本のスクレイピングをやってみたが、今回はヘッダ情報を追加してみる。
前回記事
ヘッダを設定する意味とは?
本ブログにChromeでリクエストした際のヘッダをデベロッパーツールでみてみるとこんな感じ。
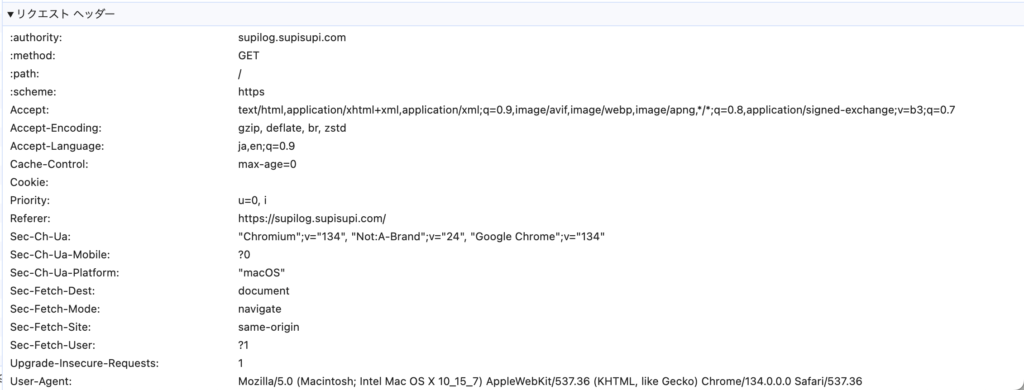
ヘッダ情報を付与する意味はどこにあるのだろうか。
WEBページを作成する側の立場にたち考えると、ヘッダ情報を元に挙動やレスポンス内容を変更することが多々ある。一番わかり易いuser-agentを例にあげると、user-agentを見て、PC/スマホ表示を切り替えることも出来るし、許可しないuser-agentからのアクセスは正常なHTMLを返却しないことも出来る。
スクレイピングの際のアクセスが、不自然なヘッダ情報だった場合に、WEBサイト側から正常なレスポンスが取得出来ない事があるのである。
Pythonでリクエストにヘッダー情報を付与
前回書いたソースコードがこちら。(ちょっと修正しています)
from bs4 import BeautifulSoup
import requests
url = "https://supilog.supisupi.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
description = soup.find_all("div", class_="header-title-ja")
print(description[0].text)
このコードは、本ブログへアクセスしているので、この状態でアクセスログを見てみます。
xx.xxx.xxx.xxx - - [23/Mar/2025:22:38:49 +0900] "GET / HTTP/1.1" 200 13805 "-" "python-requests/2.32.3" "-" "0.176"
「python-requests/2.32.3」からアクセスが来ましたよっていうログがバッチリ出てますね。
これを今回、以下のように変えてみます。
from bs4 import BeautifulSoup
import requests
url = "https://supilog.supisupi.com"
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "html.parser")
description = soup.find_all("div", class_="header-title-ja")
print(description[0].text)
headersという変数を定義して、”user-agent”を設定してみました。これは、現在のChrome(@わたしのmac)のuser-agentを設定してみたものである。
先ほどと同じように、ログを見てみるとどうだろう。
xx.xxx.xxx.xxx - - [23/Mar/2025:22:44:16 +0900] "GET / HTTP/1.1" 200 13809 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36" "-" "0.170"
headerを追加することによりuser-agentを設定する、一番わかり易い例を提示してみたが、いかがでしょうか。
まとめ
ヘッダ情報の追加や変更は、アクセスの情報を一部偽装することに他ならない。悪意あるリクエストをするために利用するのは当然ダメなので、規約の範囲内で正しく利用することが必須。
スクレイピングは情報が取得できるのが楽しくて、ついつい規約等をおろそかにしがちなので、大事にならないよう十分注意しながら行いましょう。















